CuGB CUDA Based Gradient Boosting Decision Tree 15-418 Final Project
Enzhe Lu, Jack Dong
Final Writeup Project Checkpoint Project Proposal Github CodebaseEnzhe Lu, Jack Dong
Final Writeup Project Checkpoint Project Proposal Github CodebaseCuDB is a parallel implementation of gradient boosting decision tree in CUDA on the GPU. The main focus of the project includes:
In machine learning, a decision tree is a structure used as a predictive model to conclude about the item’s target value from a set of attributes. A classification tree takes a finite set of values that represent categories, whereas a regression tree can take continuous values to represent probability. An example of regression tree is shown below in Figure 1. Each node of the decision tree represents a test on a specific attribute such as age and gender, and the outcome of the result is represented by the branch of the node. The leaf of the tree represents the corresponding target value assigned to the data entries that travel from the root to this particular leaf following the outcomes of testing the attributes.
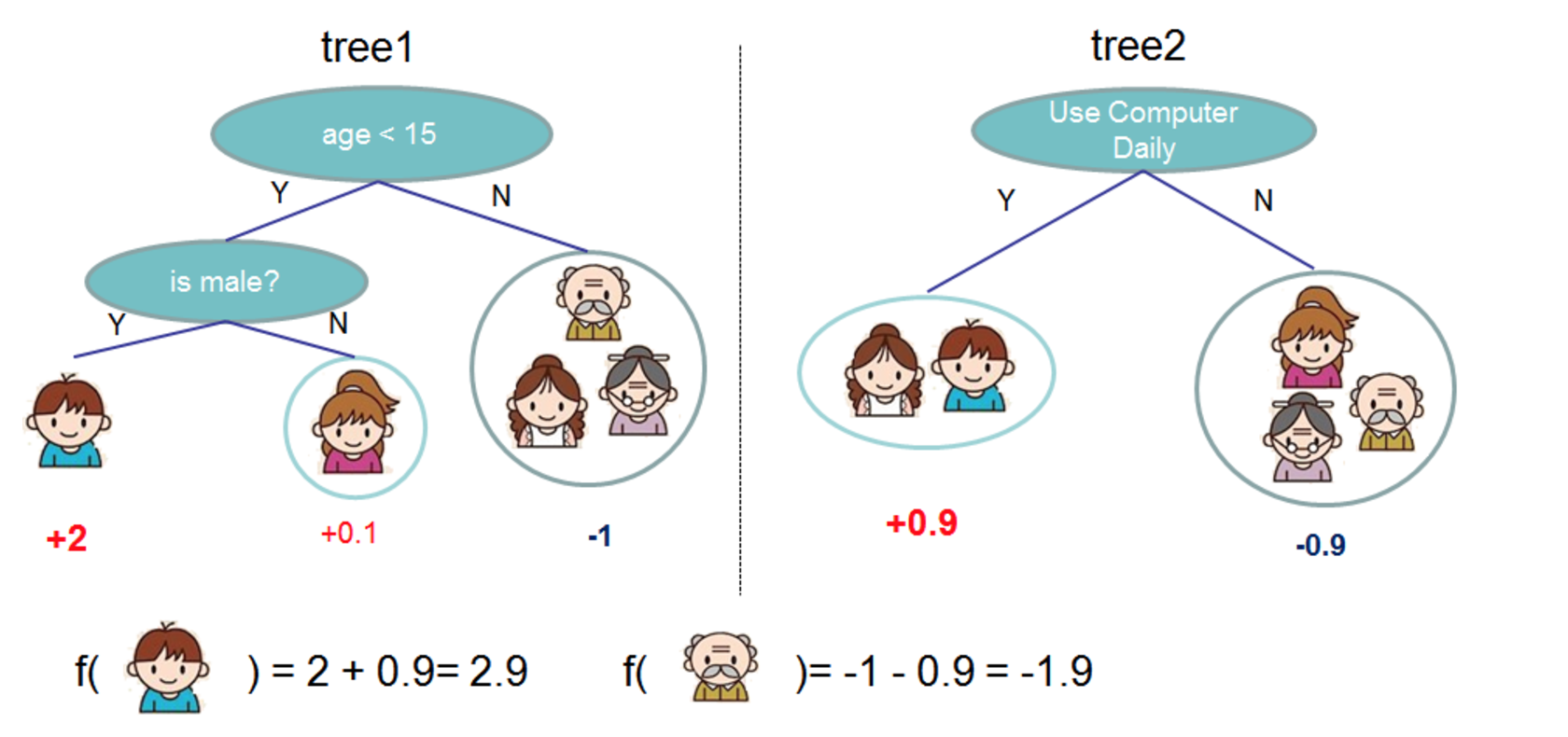
Figure 1: Decision tree example
Different algorithms can be used to learn a decision tree from training data set. CuDB uses ID3 learning to construct decision trees. The pseudocode is shown below in Figure 2. In each iteration, it traverses the set of unvisited attributes and choose select the best attribute that provides the most information. This is achieved by calculating the entropy and choose the attribute with the largest information gain. Then it splits the data according to the selected attribute, and recurse on each of the subset.

Figure 2: ID3 pseudocode
A single decision tree is a weak predictor and has its limitations. Gradient boosting is the process of building multiple trees, combining weak predictors to form a strong predicted model. The intuition behind it is that the next iteration corrects the previous error in order to improve overall reliability. The predict result is a weighted combination of each layer of the trees. A simple example is shown below in Figure 3.
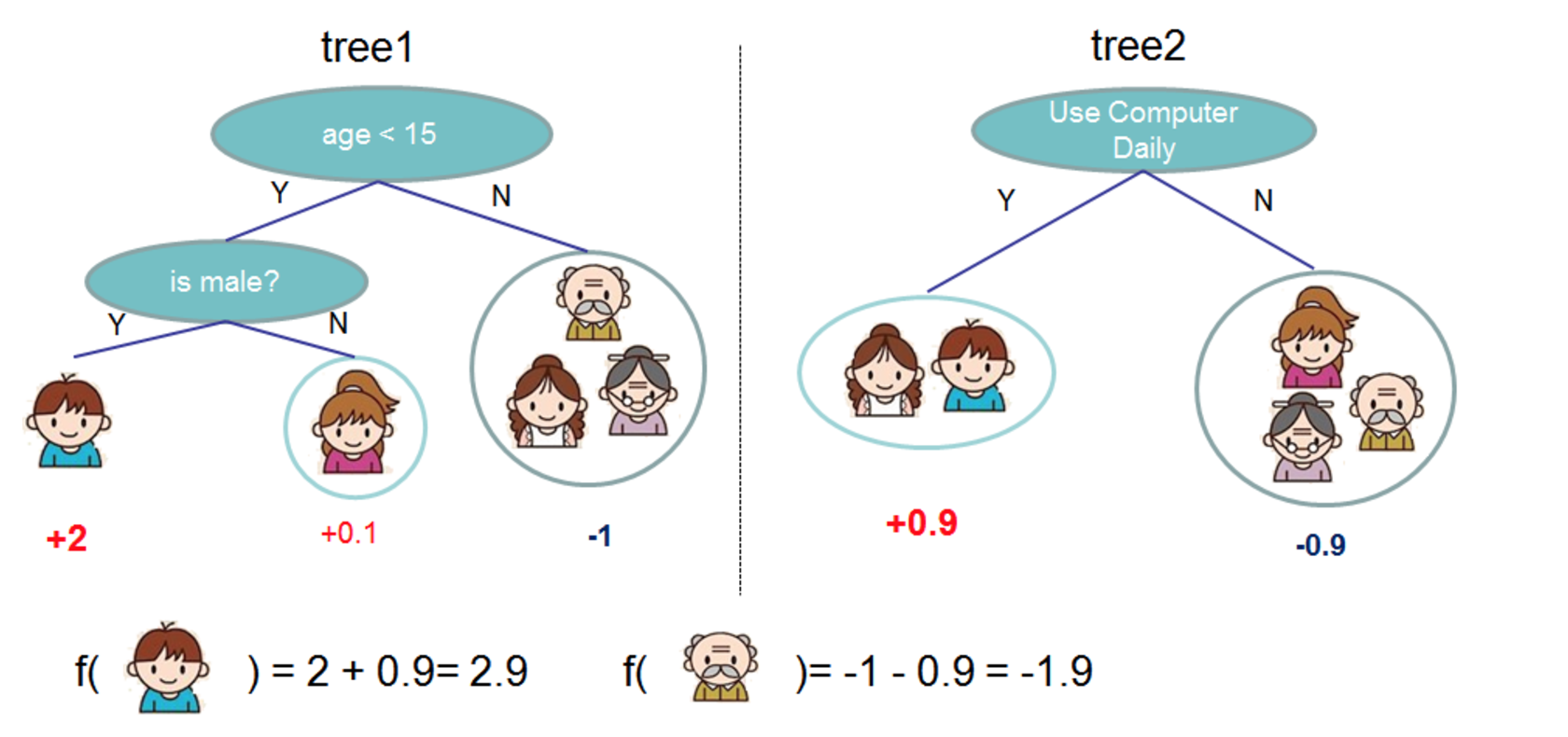
Figure 3: Gradient boosting example
The general steps of gradient boosting is first construct a naive initial tree. Then for each iteration, we construct a new tree to best reduce error using gradient of the loss function. We calculate a weight Γ for the prediction result of this tree by minimizing the new loss. The final prediction output would be the weighted sum of results obtained in all iterations.

Figure 4: Gradient boosting pseudocode
We identified some challenges with gradient boosting. First, a sequential version itself is hard to implement, requiring deep understanding of machine learning and sophisticated math operations. We decided to use our implementation as baseline. Second, we need to identify potential places to paralize. Building different levels is purely sequential, but there is significant room for parallelization in constructing individual trees. Constructing a decision tree in each iteration requires heavy computation since we need to examine all attributes of all data entries. However, the workload is relatively balanced in this operation. The last concern is the reprentation of data set, as in real world application it is quite large.
The benchmark result is obtained by running the code on the following platforms:
We obtained training and testing data sets from open source project xgboost. We slightly modified the original dataset to fit our needs. The largest training dataset contains 1 million entries with 130 attributes. The following are 2 requirements on the dataset:
The reason behind these 2 assumptions relates closely to how we represent input data set. In particular, we use a compressed data structure; instead of parsing all attributes for each data entry, we only keep the attributes that are present. This reduces data communication overhead and scales to larger data sets with memory constraints. More detailed explanation would be provided in the following sections.
We first construct a sequential version based on the Friedman’s 1999 paper of gradient boosting tree, since our dataset is a binary value attribute dataset and our model is expected to be a binary classifier. This particular model has been discussed in Friedman’s paper. In its paper, Friedman proposed one-step Newton-Raphson approximation of the linear optimization of the loss function. Pseudo-code is provided in Figure5. We directly implemented that approximation since it would take less time than computing the whole gradient of all possible outcome and selecting the best one from it.
The construction algorithm of decision tree is based on pseudo-code provided by 10-701 course, and we are using entropy approach (ID3 algorithm) to select the best attribute from whole dataset in each iteration.

Figure 5: Gradient boosting with approximation pseudocode
In the first attempt of parallelization with CUDA, we simply translate the algorithm directly into CUDA version. We have carefully analyzed the program and we discovered that our approach should be different from previous year project approach. They are using thread parallelization during construction of a decision tree. Such a top-down approach would provide great parallelization on CPU threads with OpenMP. However, since gradient boosting is construct based on weak decision trees that has lower levels, the same top-down approach would waste most of the computing power provided by CUDA and GTX1080. Thus we need to figure out a new data parallel approach. We decided to store Data in a huge GPU array of 130 attributes for each line. Each CUDA thread should read data through bias or indexing of that array. Except the second step in GDBT main loop body, all other three steps are loosely connected. They are suitable to be directly compute through function mapping. The sum of values are done with prefix-sum like reduction kernel. For building decision tree, we use extra two data length int array to represent as mask of values for each decision node. This would avoid the necessity of copying data and distribute new copy as we have done in the sequential version.
However, during the implementation, we have realized this approach does not provide good parallelization. The data communication overhead between GBDT steps area high, and each step is mapping their functions to data for only one purpose, which leads to low compute ratio. Furthermore, the way we storing the data consumes lots of memory, but lots of them are only access as an indicator of having or not having an attribute. Therefore, we made several improvements and have a different version of parallelization.
In second version of CUDA parallelization, we have done several things to improve the parallelization of our model. The first thing we do is de-code the algorithm into tiny compute steps to determine potential parallelization in each steps. Thus we figured out with the approximate approach, we are able to compute GBDT loop body step 3, 4 and step 1 of next loop with one reduction and one mapper function. We also figured out during the construction of the tree, several components could be calculating at the same time, since they do not have dependency of each other. Thus we used a single reduction to compute four different attributes to burst the construction of decision tree.
We also changed our data representation, for we have the binary attribute dataset, we could infer the value of attributes by only storing the data that have positive attributes. Thus the data set has been reduced to less than half of the original dataspace. We also stored all intermediate result in the extra few slots of dataline, which reduce the communication overhead. Each step only need to access those intermediate result they needed from the mutually agreed position of each dataline.
However, even the improvement significantly speed up our code, we are also introduced new bottleneck into our code. In this version, each thread need to sequentially loop through the entire attribute list to figure out whether a particular attribute is positive or not. Thus we modified our program the third time to deal with newly introduced bottleneck.
We observed that in the dataset, all attributes are stored in a ascending order. Thus we would be able to use Binary search to improve the speed up of finding attributes from the current dataline.
After we did this improvement, we analyzed our code again, but we haven’t be able to figure out other point for improving parallelization under current algorithm.
The final result met our expectation. Figure 6 shows how our cuda version code compare to the sequential version code. With increasing of data, cuda shows remarkable parallelization ability and it could achieve about 160x speed up with 1 million dataset.
We have further breakdown the the time of our current cuda model in 1 million dataset to determine the bottleneck of our code. As shown in Figure 7 , no matter how many data is request for copy from host memory to device memory, the CUDA memory copy time of the data does not change much. Most of the time is consumed by building the model, since we have already parallelized the current algorithm, to improve the model building time, it could be only done by adopting faster algorithms.
Distributed GBDT library xgboost does have a CUDA plugin available. However we cannot use it since it cannot compile without cmake. Based on their introductory material, we only know it has ability to execute 1 million records of 50 column in 500 iterations in 193 seconds. Our dataset does not have too much residuals, and it would left with extreme small residuals, which would be considered as zero after 25 iterations. Thus with our approach, and the dataset, we would only need 22 seconds to execute.
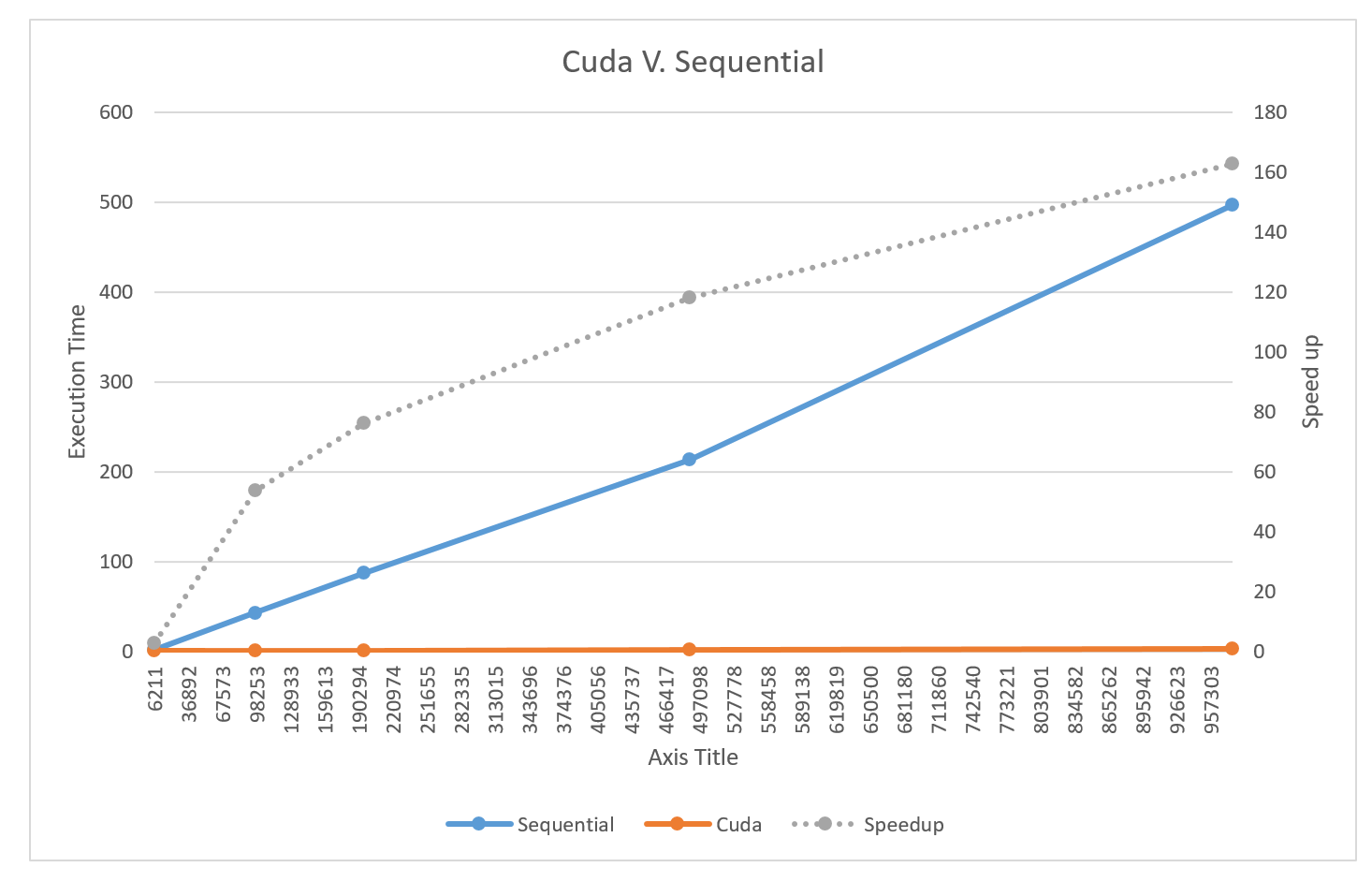
Figure 6: Performance analysis and comparison
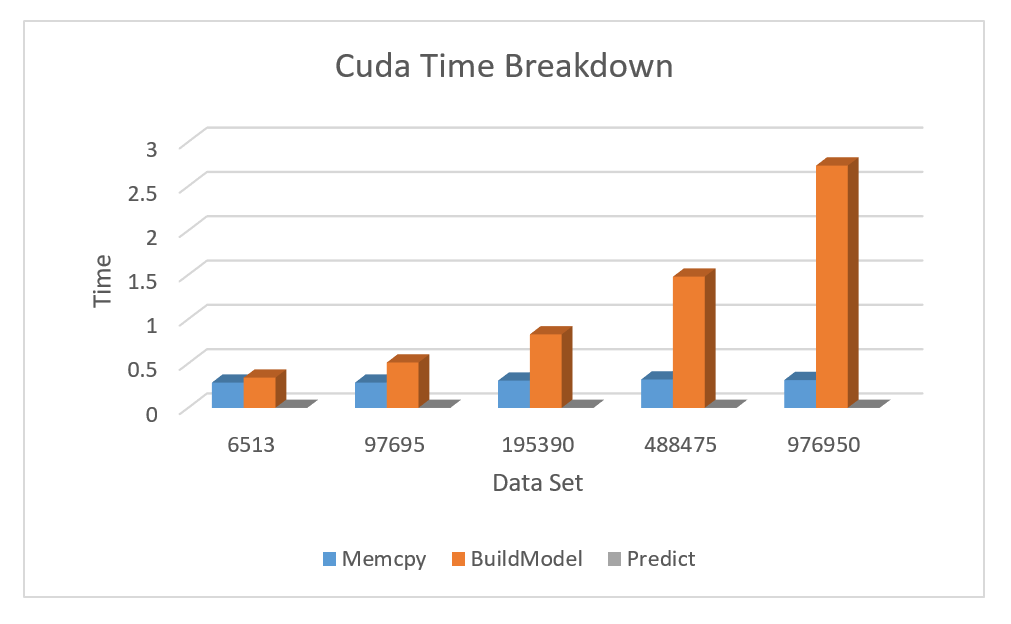
Figure 7: Parallel implementation time breakdown
In future research, it is possible to use other algorithms that consumes less time than our current algorithm which is based on Friedman 1999 paper. The paper came up with gradient boosting technique almost 20 years ago, more parallelizable approach would emerge in the passing years, thus GBDT could take less time than our approach. Such as the histogram GBDT algorithm could bring down the execution time even further.
Also, our current implementation is working on single GPU, with expansion of data, the size of dataset will exceed total GPU device memory. Therefore, in order to support larger datasets, CuDB could be extended to support either multiple GPU with a shared device memory or streamly computing of decision tree in single GPU.
Friedman, J. H. (1999). Greedy function approximation: A gradient boosting machine. Retrieved May 12, 2017, from http://projecteuclid.org/euclid.aos/1013203451.
Xing, E. (2015). Decision Tree. Lecture.
Scalable and Flexible Gradient Boosting. (n.d.). Retrieved May 12, 2017, from https://xgboost.readthedocs.io/en/latest.
Gradient boosting. (2017, April 30). Retrieved May 12, 2017, from https://en.wikipedia.org/wiki/Gradient_boosting.

Check out the project proposal on our Github. It containes our initial understanding of the problem scope as well as a drafted plan for the project. It mainly focuses on identifying challenges and determining goals and deliverables before at the initial stage of the project.
Direct to Github
Check out the project checkpoint on our Github. It demonstrates preliminary results in the middle stage. Based on the project progress, we slightly modified our schedule and project scope to reflect the unexpected changes.
Check out the project checkpoint on our Github. It demonstrates preliminary results in the middle stage. Based on the
Direct to Github
Go back to home page. If you are interested in seeing our code base, there is a direct link to the project Github repository on the home page.
Back